











 0
0


Kafka Connect



Kafka Connect — это платформа и набор инструментов для создания и запуска конвейеров данных между Apache Kafka® и другими системами данных. Он обеспечивает масштабируемый и надежный способ перемещения данных в Kafka и из него. Он имеет многоразовые плагины-коннекторы, которые можно использовать для удобной потоковой передачи данных между Kafka и различными внешними системами.
В этой статье представлен подробный обзор архитектуры Kafka и ее составляющих компонентов. Мы делимся несколькими вариантами конфигурации, примерами кода и сценариями. Мы также обсудим некоторые ограничения и лучшие практики.
Краткое изложение ключевых компонентов Kafka Connect

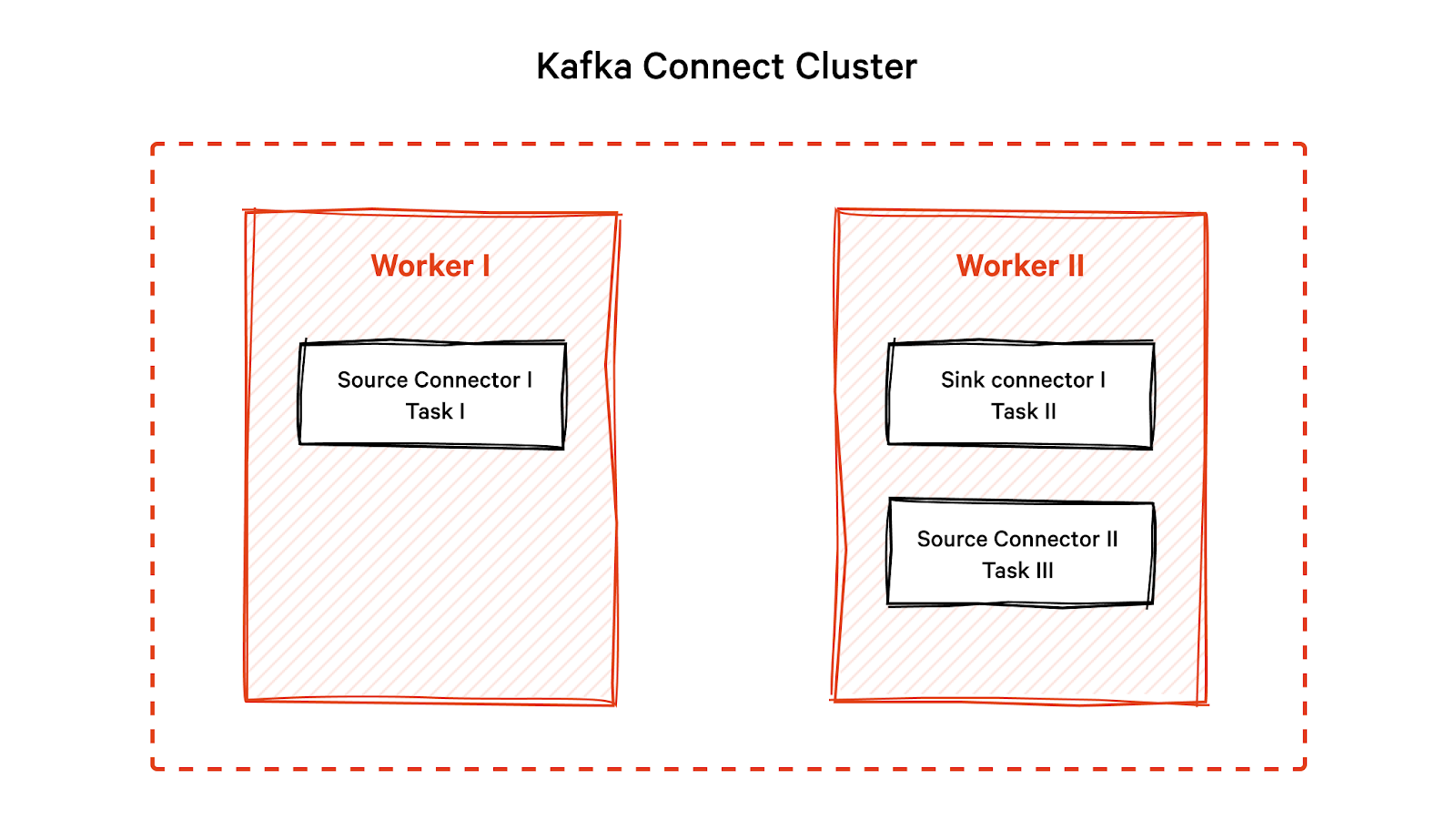
Kafka Connect workers
Вы можете настроить Kafka Connect как автономную систему с одним worker процессом (сервером) или распределенную систему с несколькими воркер процессами. Каждый воркер процесс имеет уникальный идентификатор и список соединителей и задач, за выполнение которых он отвечает.
В распределенной системе workers (воркеры) координируют разделение задач и обмениваются метаданными и информацией о конфигурации. В случае сбоя воркера другой воркер берет на себя задачи отказавшего воркера, обеспечивает отказоустойчивость и гарантирует, что обработка данных не будет нарушена.
Пример кода для запуска новых воркеров
Чтобы запустить воркер процесс, создайте файл свойств, например, connect-worker-mysql.properties. Каждый воркер процесс должен иметь уникальный group.id и rest.port configuration. Это обязательные атрибуты, необходимые для настройки воркера.
# connect-worker-mysql.properties
bootstrap.servers=localhost:9092
group.id=connect-worker-1
rest.port=8083
key.converter = org.apache.kafka.connect.json.JsonConverter
value.converter = org.apache.kafka.connect.json.JsonConverter
offset.storage.topic=connect-offsets
config.storage.topic=connect-configs
status.storage.topic=connect-status
plugin.path=/bin/mysql-connector-j-8.0.32.jar # connector JAR
Запустите воркер процесс из двоичной папки установки Kafka следующим образом:
$ bin/connect-distributed.sh config/connect-worker-mysql.properties
Эта команда запускает воркер процесс Kafka Connect в распределенном режиме и указывает файл конфигурации для воркер процесса. Каждый воркер координирует свои действия с другими воркерами в кластере, чтобы распределить нагрузку на коннекторы и задачи.
Убедитесь, что службы Kafka и ZooKeeper работают, как показано.
$ bin/zookeeper-server-start.sh config/zookeeper.properties
$ bin/kafka-server-start.sh config/server.properties
Kafka connectors
Коннекторы предоставляют уровень абстракции, который упрощает интеграцию с внешними системами. Это плагины, отвечающие за установление соединений с внешними источниками данных. Вы можете настроить каждый коннектор для получения или отправки данных определенным образом, чтобы он определял формат, в котором вы принимаете или отправляете данные.
Типы коннекторов
Kafka Connect предоставляет два типа коннектор.
Коннектор источника
Коннекторы источников опрашивают данные из внешних источников, таких как базы данных, очереди сообщений или другие приложения. Например, исходный коннектор для базы данных MySQL считывает изменения в таблице базы данных и преобразует их в записи подключения, которые затем отправляются в кластер Kafka.
Коннектор для приемника
Коннекторы приемника сохраняют данные в пункт назначения или в приемник, например в распределенную файловую систему Hadoop (HDFS), Amazon Simple Storage Service (S3) или Elasticsearch. Например, Sink Connector для Elasticsearch берет записи Connect из Kafka и записывает их в Elasticsearch в необходимом формате.
Пример кода для настройки нового коннектора
Предположим, у нас есть таблица «Заказы» для компании электронной коммерции с 5 столбцами, как показано.
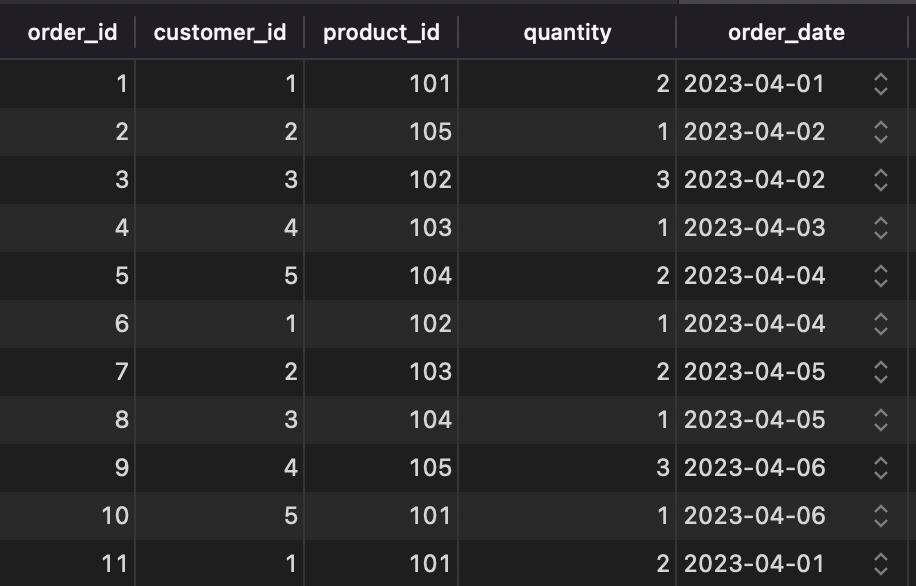
Допустим, мы хотим настроить исходный коннектор MySQL JDBC, чтобы при добавлении новой строки в таблицу заказов коннектор фиксировал изменение и выдавал сообщение. Сообщение содержит новые данные строки, сериализованные в виде объекта JSON ниже.
{
"order_id": 12,
"customer_id": 93,
"product_id": 105,
"quantity" : 2
"order_date": "2023-04-11"
}
Файл коннектор mysql-order-connector.json выглядит примерно так, как показано ниже.
{
"name": "jdbc-source-connector",
"config": {
"Connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/ecommerce",
"connection.user": "root",
"connection.password": "admin",
"mode": "incrementing",
"tasks.max": 3, // Maximum number of tasks the connector can create
"topic.prefix": "topic-", // Prefix to add to topic created by the connector
"table.whitelist": "orders", // Whitelist of tables to include in the connector's scope
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
// Converter class for the key serialization - format of key data be converted
"value.converter": "org.apache.kafka.connect.json.JsonConverter"
// Converter class for the value serialization - format of value data be converted
}
}
Вы можете передать коннектор воркер процессу, который мы создали в предыдущем разделе о воркер процессах Kafka. Воркер работает на порту REST 8083.
$ curl -X POST -H "Content-Type: application/json" --data @mysql-order-connector.json http://localhost:8083/connectors
Коннектор также создает тему под названием topic-orders. Вы можете запустить приведенный ниже код, чтобы проверить свои темы.
$ bin/kafka-topics.sh --bootstrap-server localhost:9092 --list
Теперь вы можете использовать потребительский клиент для прослушивания сообщений в файлах topic-orders.
$ bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic-orders --from-beginning
Задачи Kafka Connect
Задачи — это независимые единицы работы, которые обрабатывают определенные разделы данных. Когда вы запускаете коннектор, он разделяется на несколько задач. Каждая задача отвечает за подмножество данных коннектора. Такой подход позволяет обрабатывать данные параллельно, повышая пропускную способность.
Когда задача создается, Kafka Connect назначает ей подмножество разделов таблицы «Заказы» . Количество разделов таблицы зависит от того, как вы настроите ее в базе данных MySQL.
Если, например, вы секционируете таблицу по столбцу дат, каждой задаче может быть назначено подмножество секций на основе диапазона дат данных. Если таблица не секционирована, Kafka Connect назначает секции циклически.
Пример кода для настройки задач
В этом примере мы определяем исходный коннектор JDBC, который считывает данные из таблицы заказов в базе данных MySQL. Мы установили для свойства конфигурации Tasks.max значение 3, чтобы Kafka Connect создал три задачи для чтения данных из таблицы.
public class JdbcSourceTask extends SourceTask {
@Override
public void start(Map<String, String> props) {
// Initialize the task with configuration properties
}
@Override
public List<SourceRecord> poll() throws InterruptedException {
List<SourceRecord> records = new ArrayList<>();
// retrieve data from the JDBC source connector
List<Map<String, Object>> data = retrieveDataFromJdbcSource();
// convert data to SourceRecords
for (Map<String, Object> record : data) {
SourceRecord sourceRecord = new SourceRecord(null,null,"topic-orders",null,null,null,record);
records.add(sourceRecord);
}
return records;
}
}
Transformations Kafka Connect
Transformations (преобразования) позволяют манипулировать данными во время выполнения при перемещении сообщений через Kafka Connect. Вы можете использовать преобразования для фильтрации, изменения или дополнения сообщений до того, как они достигнут места назначения. Вы можете указать преобразования на уровне коннектора или задачи, чтобы они обрабатывали данные в определенном порядке. Например, вы можете настроить их на фильтрацию перед изменением или на изменение перед фильтрацией.
Kafka Connect предоставляет несколько встроенных преобразований, таких как RenameField, ExtractField и TimestampConverter. Вы также можете разработать собственные преобразования в соответствии с конкретными требованиями к данным.
Пример кода для добавления преобразования
Допустим, вы хотите удалить информацию, позволяющую идентифицировать личность, такую как телефон и адрес электронной почты, из SourceRecord. Вы можете написать свой собственный класс PIIRemoveTransformation и инициализировать его, как показано ниже.
@Override
public void start(Map<String, String> props) {
// Initialize the transformation
transformation = new PIIRemoveTransformation<>();
// Configure the transformation with any necessary properties
Map<String, String> transformationProps = new HashMap<>();
transformationProps.put("drop.fields", "phone,email");
transformation.configure(transformationProps);
}
Конвертеры Kafka Connect
Конвертер отвечает за сериализацию и десериализацию данных сообщения. Конвертер гарантирует, что формат данных в Kafka совместим с ожидаемым форматом внешней системы и наоборот. Он преобразует сообщение в формат, который можно отправить в кластер Kafka в виде байтовых массивов и наоборот.
Kafka Connect предоставляет готовые конвертеры для распространенных форматов данных, таких как JSON и Avro, но вы также можете разработать собственные конвертеры. Вы можете указать преобразователь на уровне соединителя или задачи, позволяя различным соединителям или задачам использовать разные форматы данных.
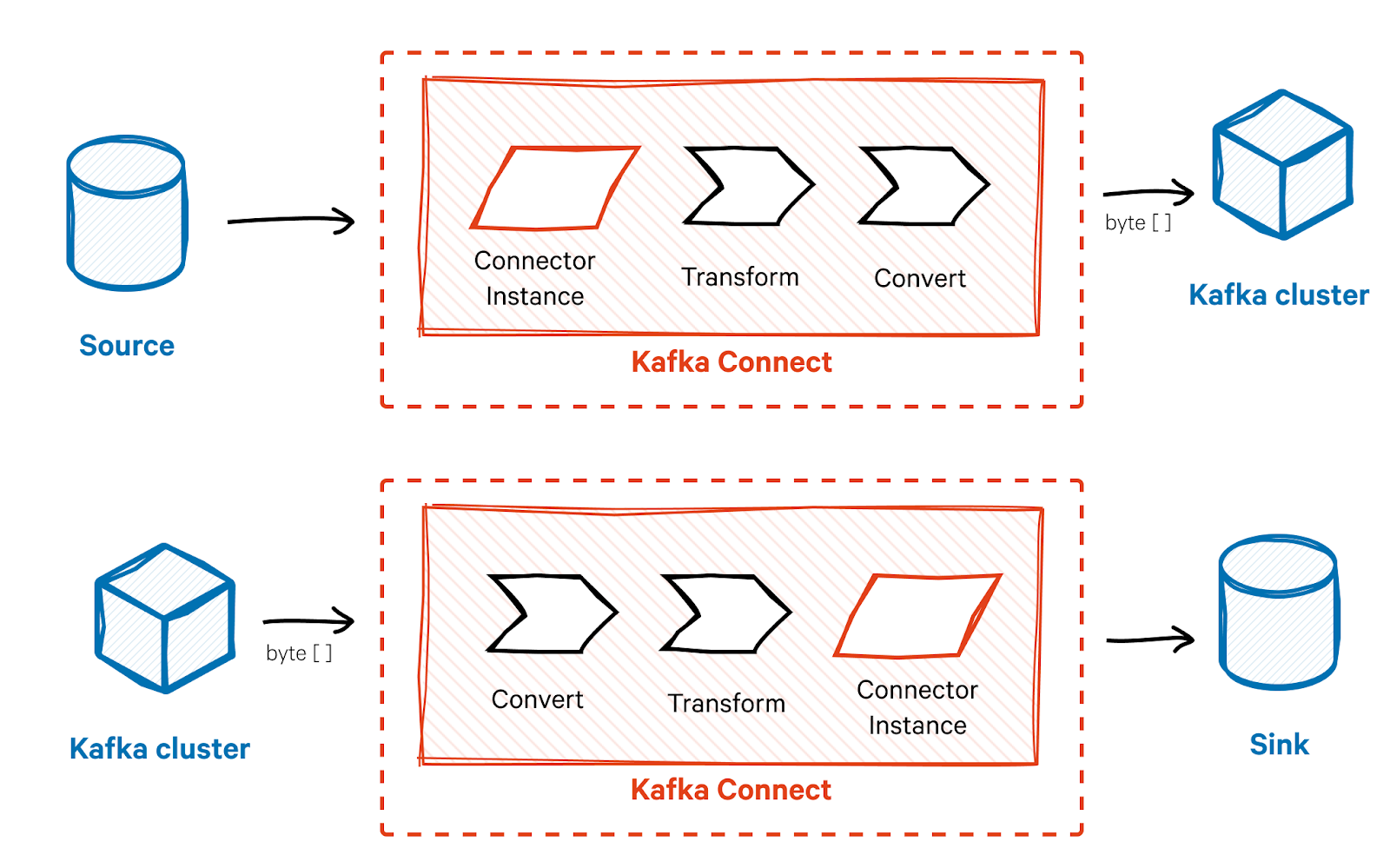
Пример кода для инициализации преобразователей
Вот как мы можем инициализировать конвертер.
public class JdbcSourceTask extends SourceTask {
@Override
public void start(Map<String, String> props) {
// Initialize the JSON converter for use
converter = new JsonConverter();
converter.configure(props, false);
}
}
Мы можем реализовать преобразование и конвертер для преобразования записи в формат JSON для каждой из записей, как показано ниже.
public class JdbcSourceTask extends SourceTask {
@Override
public void start(Map<String, String> props) {
}
@Override
public List<SourceRecord> poll() throws InterruptedException {
List<SourceRecord> records = new ArrayList<>();
// retrieve data from the JDBC source connector
List<Map<String, Object>> data = retrieveDataFromJdbcSource();
// Apply the transformation to the data
List<Map<String, Object>> transformedData = new ArrayList<>();
for (Map<String, Object> record : data) {
transformedData.add(transformation.apply(new SourceRecord(null, null, "topic-orders", null, null, null, record))); }
// Convert the transformed data to JSON
List<byte[]> jsonRecords = converter.fromConnectData("topic-orders", Schema.STRING_SCHEMA, transformedData);
// Convert the JSON records to SourceRecords
for (byte[] jsonRecord : jsonRecords) {
SourceRecord sourceRecord = new SourceRecord(null,null,"topic-orders",null,null,null,jsonRecord);
records.add(sourceRecord);
}
return records;
}
В этом примере данные сначала извлекаются из источника JDBC в виде списка карт (данные List<Map<String, Object>>), а затем преобразуются с помощью объекта преобразования. Преобразованные данные затем преобразуются в JSON с помощью объекта-конвертера.
Однако, поскольку Kafka Connect ожидает, что данные будут объектами SourceRecord, записи JSON повторно преобразуются в объекты SourceRecord, прежде чем их можно будет отправить брокеру Kafka.
Примечание. Если вы уже указали преобразователь в файле конфигурации коннектора ( mysql-order-connector.json), вам не нужно указывать его повторно в коде задачи. Когда вы запускаете рабочий процесс Kafka Connect и развертываете соединитель, воркер автоматически инициирует преобразователь, указанный в конфигурации соединителя, и передает его задаче.Очереди недоставленных сообщений Kafka Connect
Очереди недоставленных сообщений (DLQ) действуют как отказоустойчивый механизм для критических сообщений, которые не были успешно обработаны. Если сообщение не удается успешно обработать, оно перемещается в DLQ, что предотвращает потерю сообщения и позволяет разработчикам обнаружить и устранить основную причину сбоев обработки. Вы можете настроить DLQ на уровне соединителя или задачи, чтобы гарантировать, что важные сообщения не будут потеряны.
Пример кода для настройки DLQ
Вот пример того, как мы можем настроить DLQ, если некоторые записи таблицы заказов не могут быть обработаны.
@Override
public void start(Map<String, String> props) {
// Initialize the DLQ transformation
dlqTransformation = new DeadLetterQueueTransformation<>();
// Configure DLQ transformation with DLQ topic & maximum retries
Map<String, String> transformationProps = new HashMap<>();
transformationProps.put("deadletterqueue.topic.name", "orders-dlq");
transformationProps.put("deadletterqueue.max.retries", "3");
dlqTransformation.configure(transformationProps);
// Get the maximum number of retries from the configuration
maxRetries = Integer.parseInt(props.get("max.retries"));
}
@Override
public List<SourceRecord> poll() throws InterruptedException {
List<SourceRecord> sourceRecords = new ArrayList<>();
List<Map<String, Object>> data = retrieveDataFromMySql();
// Process each record
for (Map<String, Object> record : data) {
try {
sourceRecords.add(new SourceRecord(null, null, "topic-orders", null, null, null, record));
} catch (DataException e) {
// DataException indicates a non-retriable error
log.error("Failed to create SourceRecord from data: {}", e.getMessage());
// Move the failed record to the DLQ
dlqTransformation.apply(new SourceRecord(null, null, "topic-orders", null, null, null, record));
} catch (RetriableException e) {
// Retry logic here
}
}
return sourceRecords;
}
Ограничения Kafka Connect
Хотя Kafka Connect — мощный инструмент для создания масштабируемых конвейеров данных, он имеет определенные ограничения.
Ограниченные возможности
В Kafka Connect имеется менее 20 различных типов коннекторов. Если универсальный коннектор не подходит, необходимо разработать собственный. Аналогично, Kafka Connect предоставляет только базовый набор преобразований, и вам, возможно, придется написать свои собственные преобразования. Это может увеличить время и усилия, необходимые для реализации.
Сложность конфигурации
Конфигурации Kafka Connect быстро становятся сложными, особенно при работе с несколькими соединителями, задачами и преобразованиями. Это может затруднить управление, обслуживание и устранение неполадок системы. Также сложно интегрировать Kafka Connect с другими инструментами, которые, возможно, уже использует ваша организация. Это создает барьер для внедрения и замедляет процесс внедрения.
Ограниченная поддержка встроенной обработки ошибок
Основное внимание Kafka уделяется потоковой передаче данных, что приводит к ограничению встроенных возможностей обработки ошибок. Распределенный характер и потенциальные взаимозависимости между различными компонентами Kafka увеличивают сложность, затрудняя выяснение основной причины ошибки. Возможно, вам придется реализовать собственные механизмы обработки ошибок, которые могут занять много времени и не всегда быть такими надежными, как встроенные возможности, предоставляемые другими инструментами интеграции данных и ETL.
Грамотное восстановление после сложных ошибок также является сложной задачей в Kafka, поскольку может не существовать четкого пути возобновления обработки данных после возникновения ошибки. Это может привести к снижению эффективности и потребовать дальнейшего ручного вмешательства для восстановления нормальной работы.
Проблемы с производительностью
Большинству приложений требуются высокоскоростные конвейеры данных для сценариев использования в режиме реального времени. Однако в зависимости от типа соединителя и объема данных Kafka Connect может вносить некоторую задержку в вашу систему. Это может не подойти, если ваше приложение не терпит задержек.
Однако, исходя из этих ограничений, было бы неверно утверждать, что Kafka Connect не является хорошим выбором; у него есть множество преимуществ, которые намного перевешивают его ограничения.
Лучшие практики для Kafka Connect
Kafka Connect — мощный инструмент для создания масштабируемых конвейеров данных, но для обеспечения успешного внедрения и оперативного внедрения необходимо следовать передовым практикам. Вот несколько советов и рекомендаций, которые помогут избежать ошибок и добиться успеха с Kafka Connect.
Планируйте свой конвейер
Прежде чем начать процесс внедрения, определите источники и места назначения ваших данных и убедитесь, что ваш конвейер масштабируем и может обрабатывать растущие объемы данных. Кроме того, обязательно обеспечьте соответствующую инфраструктуру. Для оптимальной производительности Kafka Connect требуется масштабируемая и надежная инфраструктура. Используйте кластерную архитектуру с достаточными ресурсами для обработки нагрузки конвейера данных и обеспечения высокой доступности вашей инфраструктуры.
Используйте реестр схем
Использование реестра схем в Kafka Connect может быть полезным, поскольку позволяет централизованно хранить схемы и управлять ими. Это помогает поддерживать согласованность схемы во всех системах, снижает вероятность повреждения данных и упрощает эволюцию схемы.
Настройка производительности
Важно спроектировать и настроить соединение Kafka для будущего масштабирования и производительности. Например, вы можете реализовать подходящую стратегию секционирования, чтобы равномерно распределить данные по разделам. Это поможет вашему кластеру Kafka Connect эффективно управлять большим объемом данных. Аналогичным образом вы можете использовать эффективный формат сериализации, такой как Avro или Protobuf, для более быстрой передачи данных по сети.
Мониторинг
Мониторинг имеет решающее значение для обеспечения бесперебойного функционирования вашего конвейера данных. Используйте инструменты мониторинга, чтобы отслеживать производительность развертывания Kafka Connect, а также быстро выявлять и устранять любые проблемы. Вы также можете рассмотреть возможность внедрения очереди недоставленных писем (DLQ) в качестве системы безопасности для захвата и обработки любых сообщений, которые неоднократно терпят неудачу во время повторных попыток, гарантируя, что они не потеряются.
Заключение
Kafka Connect — полезный инструмент для создания гибких, крупномасштабных конвейеров данных в реальном времени с помощью Apache Kafka. Он использует соединители, чтобы упростить перемещение данных между Kafka и другими системами, обеспечивая масштабируемое и адаптируемое решение. Компоненты Kafka Connect, включая исполнителей, задачи, преобразователи и преобразования, позволяют перемещать данные между несколькими различными исходными и целевыми системами, преобразовывать данные из одной формы в другую и преобразовывать данные для аналитики. Вы также можете настроить очереди недоставленных писем для обработки ошибок. Хотя Kafka Connect имеет некоторые ограничения, для успешного внедрения вы можете следовать рекомендациям.