











 0
0


Использование Elasticsearch в Python



Это руководство научит вас основам использования Elasticsearch в Python. Вы узнаете, как настроить кластер Elasticsearch на своем компьютере, создать индекс, добавить данные в этот индекс и выполнить поиск по данным.
Что такое Elasticsearch?
Elasticsearch — это распределенная, быстрая и простая в масштабировании поисковая система, способная обрабатывать текстовые, числовые, геопространственные, структурированные и неструктурированные данные. Это популярная поисковая система для приложений, веб-сайтов и аналитики журналов. Это также ключевой компонент Elastic Stack (также известного как ELK), в который входят Logstash и Kibana.
Чтобы понять внутреннюю работу Elasticsearch, представьте, что это два разных процесса. Один из них — прием, который нормализует и обогащает необработанные данные перед индексацией с использованием инвертированного индекса . Второй — извлечение, которое позволяет пользователям извлекать данные путем написания запросов, выполняемых к индексу.
Это все, что вам нужно знать на данный момент. Далее вы подготовите локальную среду для запуска ES-кластера.
Предварительные условия
Прежде чем приступить к работе, вам необходимо настроить несколько вещей. Убедитесь, что они у вас есть, и увидимся в следующем разделе:
- Установите docker.
- Создайте виртуальную среду и установите необходимые пакеты. Если хотите
venv, вы можете запустить эти команды:
python3 -m venv .venv
source .venv/bin/activate
python3 -m pip install pandas==1.4.3 notebook==6.3.0 elasticsearch==8.7.0
Все хорошо? Давайте продолжим.
Создайте локальный кластер Elasticsearch
Самый простой способ запустить Elasticsearch локально — использовать Docker.
Откройте терминал и запустите этот код, чтобы запустить одноузловой ES-кластер, который вы можете использовать для локальной разработки:
docker run --rm -p 9200:9200 -p 9300:9300 -e "xpack.security.enabled=false" -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:8.7.0
Запустив эту команду, вы увидите на своем терминале много текста. Но не волнуйтесь, это нормально!
Эта команда запустит кластер Elasticsearch на вашем компьютере. Здесь есть несколько вещей, которые нужно распаковать:
docker run: это команда, которую вы используете для запуска образа внутри контейнера.--rm: этот параметр сообщает Docker, что нужно очистить контейнер и удалить файловую систему при выходе из контейнера.-p 9200:9200 -p 9300:9300: сообщает Docker, какие порты открыть на сетевом интерфейсе контейнера.-e "xpack.security.enabled=false": Это указывает Docker начать работу с отключенными функциями безопасности . Для этого параметра должно быть установлено значение true (или исключено) при работе в рабочей среде.-e "discovery.type=single-node": это указывает Docker создать кластер с одним узлом.
Подключитесь к своему кластеру
Создайте новый блокнот Jupyter и запустите следующий код, чтобы подключиться к только что созданному кластеру ES.
from elasticsearch import Elasticsearch
es = Elasticsearch("http://localhost:9200")
es.info().body
Это подключится к вашему локальному кластеру. Обязательно используйте httpвместо https. Если вы этого не сделаете, вы получите сообщение об ошибке, поскольку у вас нет действующего сертификата SSL/TLS. Обратите внимание, что в рабочей среде вам понадобится использовать https.
Если все прошло хорошо, вы должны увидеть результат, аналогичный моему:
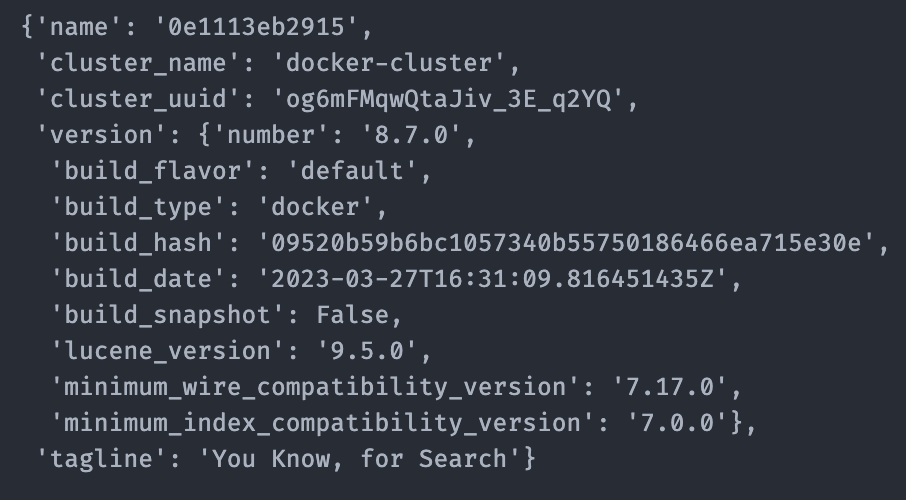
Теперь давайте добавим некоторые данные в ваш недавно созданный индекс!
Прочтите набор данных
Используйте pandas, чтобы прочитать набор данных и получить из него выборку из 5000 строк. Вы будете использовать образец, потому что в противном случае индексация документов займет много времени.
import pandas as pd
df = (
pd.read_csv("wiki_movie_plots_deduped.csv")
.dropna()
.sample(5000, random_state=42)
.reset_index()
)
Далее вы создадите индекс для хранения этих данных.
Создать индекс
Индекс — это набор документов, которые Elasticsearch хранит и представляет через структуру данных, называемую инвертированным индексом . Эта структура данных идентифицирует документы, в которых встречается каждое уникальное слово.
Elasticsearch создает этот инвертированный индекс, когда вы индексируете документы. Таким образом он может выполнять быстрый полнотекстовый поиск.
Как вы понимаете, прежде чем приступить к индексированию документов, необходимо сначала создать индекс. Вот как это можно сделать:
mappings = {
"properties": {
"title": {"type": "text", "analyzer": "english"},
"ethnicity": {"type": "text", "analyzer": "standard"},
"director": {"type": "text", "analyzer": "standard"},
"cast": {"type": "text", "analyzer": "standard"},
"genre": {"type": "text", "analyzer": "standard"},
"plot": {"type": "text", "analyzer": "english"},
"year": {"type": "integer"},
"wiki_page": {"type": "keyword"}
}
}
es.indices.create(index="movies", mappings=mappings)
Этот код создаст новый индекс, вызываемый movies с использованием кластера, который вы настроили ранее.
Строки с 1 по 12 определяют сопоставление, которое сообщает индексу, как следует хранить документы. Сопоставление определяет типы данных, назначенные каждому полю в документах, хранящихся в вашем индексе.
Вы можете использовать динамическое или явное сопоставление . При динамическом сопоставлении Elasticsearch определяет, какой тип данных следует использовать для каждого поля.
При явном сопоставлении каждый тип данных определяется вручную. Последнее дает вам большую свободу в определении каждого поля, поэтому вы использовали его в приведенном выше коде.
Теперь вы начнете добавлять данные в свой индекс.
Добавьте данные в свой индекс
Вы можете использовать es.index() или bulk() для добавления данных в индекс. es.index()добавляет по одному элементу за раз и bulk() позволяет добавлять несколько элементов одновременно.
Вы можете использовать любой из двух методов для добавления данных в индекс:
С использованием es.index()
Вот как вы используете es.index() для хранения своих данных:
for i, row in df.iterrows():
doc = {
"title": row["Title"],
"ethnicity": row["Origin/Ethnicity"],
"director": row["Director"],
"cast": row["Cast"],
"genre": row["Genre"],
"plot": row["Plot"],
"year": row["Release Year"],
"wiki_page": row["Wiki Page"]
}
es.index(index="movies", id=i, document=doc)
Этот код перебирает строки набора данных, которые вы прочитали ранее, и добавляет в индекс соответствующую информацию из каждой строки, используя es.index(). Вы используете три параметра этого метода:
index="movies": сообщает Elasticsearch, какой индекс использовать для хранения данных. В кластере может быть несколько индексов.id=i: это идентификатор документа при добавлении его в индекс. В этом случае вы устанавливаете номер строки.document=doc: указывает Elasticsearch, какую информацию он должен хранить.
С использованием bulk()
Вот как вы используете bulk() для хранения своих данных:
from elasticsearch.helpers import bulk
bulk_data = []
for i,row in df.iterrows():
bulk_data.append(
{
"_index": "movies",
"_id": i,
"_source": {
"title": row["Title"],
"ethnicity": row["Origin/Ethnicity"],
"director": row["Director"],
"cast": row["Cast"],
"genre": row["Genre"],
"plot": row["Plot"],
"year": row["Release Year"],
"wiki_page": row["Wiki Page"],
}
}
)
bulk(es, bulk_data)
bulk()требует ту же информацию, что и .index(): имя индекса, идентификатор документа и сам документ. Но вместо того, чтобы добавлять каждый элемент по одному, вы должны создать список словарей со всеми документами, которые вы хотите добавить в индекс. Затем вы передаете эту информацию и объект кластера в bulk().
После добавления данных вы можете убедиться, что они работают, подсчитав количество элементов в индексе:
es.indices.refresh(index="movies")
es.cat.count(index="movies", format="json")
Ваш вывод должен выглядеть так:

Поиск данных с помощью Elasticsearch
Наконец, вы захотите начать поиск, используя свой индекс. Elasticsearch имеет мощный DSL , который позволяет создавать запросы многих типов.
Вот пример поиска фильмов с Джеком Николсоном в главной роли, но режиссером которых не является Роман Полански:
resp = es.search(
index="movies",
query={
"bool": {
"must": {
"match_phrase": {
"cast": "jack nicholson",
}
},
"filter": {"bool": {"must_not": {"match_phrase": {"director": "roman polanski"}}}},
},
},
)
resp.body
Когда вы запустите этот код, вы должны получить очень длинный ответ, который выглядит примерно так:
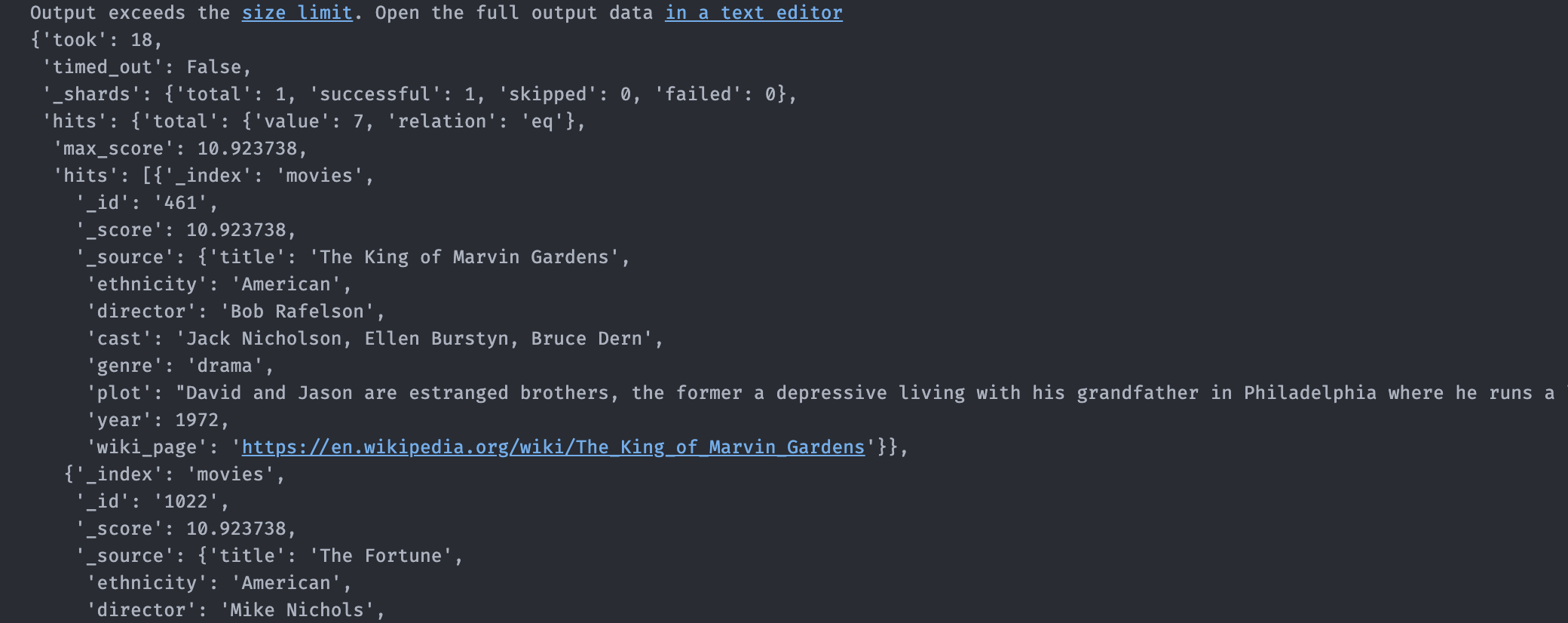
Теперь пришло время попробовать создать собственный поиск. Хорошей отправной точкой является документация по запросам DSL .
Удалить документы из индекса
Вы можете использовать следующий код для удаления документов из индекса:
es.delete(index="movies", id="2500")
Приведенный выше код удалит документ с идентификатором 2500 из индексных фильмов.
Удалить индекс
Наконец, если по какой-либо причине вы хотите удалить индекс (и все входящие в него документы), вот как это сделать:
es.indices.delete(index='movies')
Заключение
В этом руководстве мы изучили основы Elasticsearch и узнали, как его использовать. Это будет полезно в вашей карьере, поскольку в какой-то момент вы наверняка столкнетесь с Elasticsearch.
Если у вас есть какие-либо вопросы или отзывы, дайте нам знать в комментариях!




