











 0
0


Использование Elasticsearch с Spring Boot



В данной статье, мы будем использовать Spring Data Elasticsearch, чтобы продемонстрировать возможности индексирования и поиска Elasticsearch, а ближе к концу создадим простое поисковое приложение для поиска продуктов в ассортименте.
Spring Data Elasticsearch предоставляет простой интерфейс для выполнения операций в Elasticsearch в качестве альтернативы непосредственному использованию REST API:
- хранение документов в индексе,
- поиск по индексу с помощью мощных запросов для получения этих документов и
- запускать аналитические функции для данных.
Концепции Elasticsearch
Самый простой способ познакомиться с концепциями Elasticsearch — провести аналогию с базой данных, как показано в этой таблице:

Любые данные, которые мы хотим найти или проанализировать, хранятся в виде документа в индексе. В Spring Data мы представляем документ в форме POJO и украшаем его аннотациями, чтобы определить сопоставление с документом Elasticsearch.
В отличие от базы данных, текст, хранящийся в Elasticsearch, сначала обрабатывается различными анализаторами. Анализатор по умолчанию разбивает текст по обычным разделителям слов, таким как пробелы и знаки препинания, а также удаляет распространенные английские слова.
Если мы сохраним текст «Небо голубое», то анализатор сохранит его как документ с «терминами» «небо» и «голубой». Мы сможем выполнить поиск в этом документе по тексту в виде «голубое небо», «небо» или «синий» со степенью соответствия, указанной в виде оценки.
Помимо текста, Elasticsearch может хранить другие типы данных, как Field Type.
Запуск экземпляра Elasticsearch
Прежде чем идти дальше, давайте запустим экземпляр Elasticsearch, который мы будем использовать для запуска наших примеров. Существует множество способов запуска экземпляра Elasticsearch:
- Использование хостинг сервера
- Использование управляемого сервиса от поставщика облачных услуг, такого как AWS или Azure.
- Сделай сам, установив Elasticsearch в кластер виртуальных машин.
- Запуск образа Docker
Мы будем использовать образ Docker из Dockerhub, которого достаточно для нашего демонстрационного приложения. Давайте запустим наш экземпляр Elasticsearch, выполнив run команду Docker:
docker run -p 9200:9200 \ -e "discovery.type=single-node" \ docker.elastic.co/elasticsearch/elasticsearch:7.10.0
Выполнение этой команды запустит экземпляр Elasticsearch, прослушивающий порт 9200. Мы можем проверить состояние экземпляра, нажав URL-адрес http://localhost:9200, и проверив полученный результат в нашем браузере:
{
"name" : "8c06d897d156",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "Jkx..VyQ",
"version" : {
"number" : "7.10.0",
...
},
"tagline" : "You Know, for Search"
}
Мы должны получить приведенный выше вывод, если наш экземпляр Elasticsearch запущен успешно.
Индексирование и поиск с помощью REST API
Доступ к операциям Elasticsearch осуществляется через REST API. Существует два способа добавления документов в индекс:
- добавление одного документа за раз или
- массовое добавление документов.
API для добавления отдельных документов принимает документ в качестве параметра.
Простой запрос PUT к экземпляру Elasticsearch для хранения документа выглядит следующим образом:
PUT /messages/_doc/1
{
"message": "The Sky is blue today"
}
Это сохранит сообщение «Небо сегодня голубое» как документ в индексе с именем «сообщения».
Мы можем получить этот документ с помощью поискового запроса, отправленного в search REST API:
GET /messages/search
{
"query":
{
"match": {"message": "blue sky"}
}
}
Здесь мы отправляем запрос типа match для получения документов, соответствующих строке «голубое небо». Мы можем задать запросы для поиска документов несколькими способами. Elasticsearch предоставляет Query DSL (язык, специфичный для предметной области) на основе JSON для определения запросов.
Для массового добавления нам необходимо предоставить документ JSON, содержащий записи, подобные следующему фрагменту:
POST /_bulk
{"index":{"_index":"productindex"}}
{"_class":"..Product","name":"Corgi Toys .. Car",..."manufacturer":"Hornby"}
{"index":{"_index":"productindex"}}
{"_class":"..Product","name":"CLASSIC TOY .. BATTERY"...,"manufacturer":"ccf"}
Операции Elasticsearch с данными Spring
У нас есть два способа доступа к Elasticsearch с помощью Spring Data, как показано здесь:
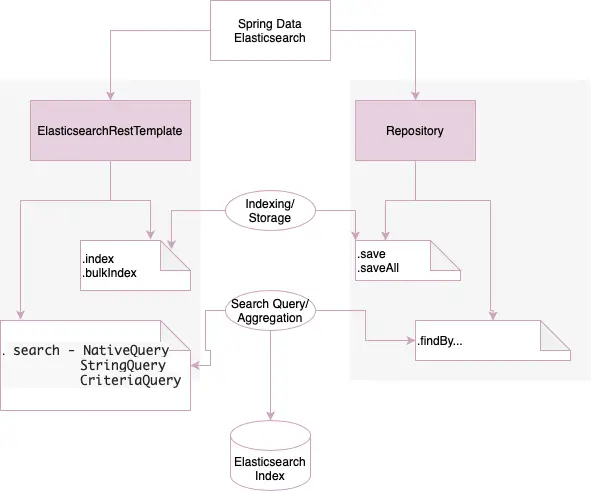 Репозитории : мы определяем методы в интерфейсе, а запросы Elasticsearch генерируются на основе имен методов во время выполнения.
Репозитории : мы определяем методы в интерфейсе, а запросы Elasticsearch генерируются на основе имен методов во время выполнения.ElasticsearchRestTemplate: мы создаем запросы с цепочками методов и собственными запросами, чтобы иметь больше контроля над созданием запросов Elasticsearch в относительно сложных сценариях.
В следующих разделах мы рассмотрим эти два способа более подробно.
Создание приложения и добавление зависимостей
Давайте сначала создадим наше приложение с помощью Spring Initializr , включив в него зависимости для Web, Timeleaf и Lombok. Мы добавляем thymeleafзависимости для добавления пользовательского интерфейса в приложение.
Теперь мы добавим spring-data-elasticsearch зависимость в наш Maven pom.xml:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
</dependency>
Подключение к экземпляру Elasticsearch
Spring Data Elasticsearch использует клиент REST высокого уровня Java (JHLC) для подключения к серверу Elasticsearch. JHLC — клиент Elasticsearch по умолчанию. Для этого мы создадим конфигурацию Spring Bean:
@Configuration
@EnableElasticsearchRepositories(basePackages
= "io.pratik.elasticsearch.repositories")
@ComponentScan(basePackages = { "io.pratik.elasticsearch" })
public class ElasticsearchClientConfig extends
AbstractElasticsearchConfiguration {
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration =
ClientConfiguration
.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
Здесь мы подключаемся к нашему экземпляру Elasticsearch, который мы запустили ранее. Мы можем дополнительно настроить соединение, добавив дополнительные свойства, такие как включение SSL, установка таймаутов и т. д.
Для отладки и диагностики мы включим ведение журнала запросов/ответов на транспортном уровне в нашей конфигурации журналирования в logback-spring.xml:
<logger name="org.springframework.data.elasticsearch.client.WIRE" level="trace"/>
Представление документа
В нашем примере мы будем искать товары по названию, бренду, цене или описанию. Итак, для хранения продукта в виде документа в Elasticsearch мы представим продукт как POJO и украсим его аннотациями Fieldдля настройки сопоставления с Elasticsearch, как показано здесь:
@Document(indexName = "productindex")
public class Product {
@Id
private String id;
@Field(type = FieldType.Text, name = "name")
private String name;
@Field(type = FieldType.Double, name = "price")
private Double price;
@Field(type = FieldType.Integer, name = "quantity")
private Integer quantity;
@Field(type = FieldType.Keyword, name = "category")
private String category;
@Field(type = FieldType.Text, name = "desc")
private String description;
@Field(type = FieldType.Keyword, name = "manufacturer")
private String manufacturer;
...
}
В @Document аннотации указывается имя индекса.
Аннотация @Id делает аннотированное поле _id нашим документом, являясь уникальным идентификатором в этом индексе. Поле idимеет ограничение в 512 символов.
Аннотация @Field настраивает тип поля. Мы также можем установить имя для другого имени поля.
Индекс по имени productindex создается в Elasticsearch на основе этих аннотаций.
Индексирование и поиск с помощью репозитория данных Spring
Репозитории предоставляют наиболее удобный способ доступа к данным в Spring Data с помощью методов поиска. Запросы Elasticsearch создаются на основе имен методов. Однако мы должны быть осторожны, чтобы не получить неэффективные запросы и не создать высокую нагрузку на кластер.
Давайте создадим интерфейс репозитория Spring Data, расширив интерфейс ElasticsearchRepository :
public interface ProductRepository
extends ElasticsearchRepository<Product, String> {
}
Здесь ProductRepository класс наследует такие методы save(), как saveAll(), find(), и findAll() включены из ElasticsearchRepository интерфейса.
Индексирование
Теперь мы сохраним некоторые продукты в индексе, вызвав save()метод для хранения одного продукта и saveAll() метод для массового индексирования. Перед этим мы поместим интерфейс репозитория в сервисный класс:
@Service
public class ProductSearchServiceWithRepo {
private ProductRepository productRepository;
public void createProductIndexBulk(final List<Product> products) {
productRepository.saveAll(products);
}
public void createProductIndex(final Product product) {
productRepository.save(product);
}
}
Когда мы вызываем эти методы из JUnit, мы видим в журнале трассировки, что REST API вызывает индексацию и массовую индексацию.
Поиск
Для выполнения наших требований к поиску мы добавим методы поиска в интерфейс нашего репозитория:
public interface ProductRepository
extends ElasticsearchRepository<Product, String> {
List<Product> findByName(String name);
List<Product> findByNameContaining(String name);
List<Product> findByManufacturerAndCategory
(String manufacturer, String category);
}
Запустив метод findByName() с помощью JUnit, мы можем увидеть запросы Elasticsearch, созданные в журналах трассировки, перед отправкой на сервер:
TRACE Sending request POST /productindex/_search? ..:
Request body: {.."query":{"bool":{"must":[{"query_string":{"query":"apple","fields":["name^1.0"],..}
Аналогично, запустив метод findByManufacturerAndCategory(), мы можем увидеть сформированный запрос с двумя query_string параметрами, соответствующими двум полям — «производитель» и «категория»:
TRACE .. Sending request POST /productindex/_search..:
Request body: {.."query":{"bool":{"must":[{"query_string":{"query":"samsung","fields":["manufacturer^1.0"],..}},{"query_string":{"query":"laptop","fields":["category^1.0"],..}}],..}},"version":true}
Существует множество комбинаций шаблонов именования методов , которые генерируют широкий спектр запросов Elasticsearch.
Индексирование и поиск с помощьюElasticsearchRestTemplate
Репозиторий Spring Data может не подойти, когда нам нужен больший контроль над тем, как мы разрабатываем наши запросы, или когда команда уже имеет опыт работы с синтаксисом Elasticsearch.
В этой ситуации мы используем ElasticsearchRestTemplate. Это новый клиент Elasticsearch, основанный на HTTP, заменяющий TransportClient предыдущих версий, в которых использовался бинарный протокол между узлами.
ElasticsearchRestTemplate реализует интерфейс ElasticsearchOperations, который выполняет тяжелую работу по низкоуровневому поиску и действиям по кластеризации.
Индексирование
Этот интерфейс имеет методы index() для добавления одного документа и bulkIndex() добавления нескольких документов в индекс. Фрагмент кода здесь показывает использование bulkIndex() для добавления нескольких продуктов в индекс «productindex»:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public List<String> createProductIndexBulk
(final List<Product> products) {
List<IndexQuery> queries = products.stream()
.map(product->
new IndexQueryBuilder()
.withId(product.getId().toString())
.withObject(product).build())
.collect(Collectors.toList());;
return elasticsearchOperations
.bulkIndex(queries,IndexCoordinates.of(PRODUCT_INDEX));
}
...
}
Документ, который необходимо сохранить, заключен в IndexQueryобъект. Метод bulkIndex() принимает на вход список IndexQuery объектов и имя индекса, заключенное внутри него IndexCoordinates. Мы получаем трассировку REST API для запроса, bulkкогда выполняем этот метод:
Sending request POST /_bulk?timeout=1m with parameters:
Request body: {"index":{"_index":"productindex","_id":"383..35"}}
{"_class":"..Product","id":"383..35","name":"New Apple..phone",..manufacturer":"apple"}
..
{"_class":"..Product","id":"d7a..34",.."manufacturer":"samsung"}
Далее мы используем index() метод для добавления одного документа:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public String createProductIndex(Product product) {
IndexQuery indexQuery = new IndexQueryBuilder()
.withId(product.getId().toString())
.withObject(product).build();
String documentId = elasticsearchOperations
.index(indexQuery, IndexCoordinates.of(PRODUCT_INDEX));
return documentId;
}
}
Соответственно, трассировка показывает запрос REST API PUT для добавления одного документа.
Sending request PUT /productindex/_doc/59d..987..:
Request body: {"_class":"..Product","id":"59d..87",..,"manufacturer":"dell"}
Поиск
ElasticsearchRestTemplate также имеет search() метод поиска документов в индексе. Эта операция поиска напоминает запросы Elasticsearch и строится путем создания Query объекта и его передачи методу поиска.
Объект Query имеет три варианта — NativeQuery, StringQuery, и CriteriaQuery в зависимости от того, как мы строим запрос. Построим несколько запросов для поиска товаров.
NativeQuery
NativeQuery обеспечивает максимальную гибкость при построении запроса с использованием объектов, представляющих такие конструкции Elasticsearch, как агрегация, фильтрация и сортировка. Вот NativeQuery для поиска продуктов, соответствующих конкретному производителю:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public void findProductsByBrand(final String brandName) {
QueryBuilder queryBuilder =
QueryBuilders
.matchQuery("manufacturer", brandName);
Query searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.build();
SearchHits<Product> productHits =
elasticsearchOperations
.search(searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX));
}
}
Здесь мы создаем запрос с NativeSearchQueryBuilder использованием a MatchQueryBuilder для указания запроса на совпадение, содержащего поле «производитель».
StringQuery
A StringQuery дает полный контроль, позволяя использовать собственный запрос Elasticsearch в виде строки JSON, как показано здесь:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public void findByProductName(final String productName) {
Query searchQuery = new StringQuery(
"{\"match\":{\"name\":{\"query\":\""+ productName + "\"}}}\"");
SearchHits<Product> products = elasticsearchOperations.search(
searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX_NAME));
...
}
}
В этом фрагменте кода мы указываем простой match запрос для получения продуктов с определенным именем, отправленным в качестве параметра метода.
CriteriaQuery
С его помощью CriteriaQueryмы можем строить запросы, не зная никакой терминологии Elasticsearch. Запросы строятся с использованием цепочки методов с объектами Criteria. Каждый объект определяет некоторые критерии, используемые для поиска документов:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public void findByProductPrice(final String productPrice) {
Criteria criteria = new Criteria("price")
.greaterThan(10.0)
.lessThan(100.0);
Query searchQuery = new CriteriaQuery(criteria);
SearchHits<Product> products = elasticsearchOperations
.search(searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX_NAME));
}
}
В этом фрагменте кода мы формируем запрос CriteriaQueryдля получения продуктов, цена которых больше 10,0 и меньше 100,0.
Создание поискового приложения
Теперь мы добавим в наше приложение пользовательский интерфейс, чтобы увидеть поиск продуктов в действии. Пользовательский интерфейс будет иметь поле ввода для поиска продуктов по названию или описанию. В поле ввода будет функция автозаполнения, позволяющая отображать список предложений на основе доступных продуктов, как показано здесь:
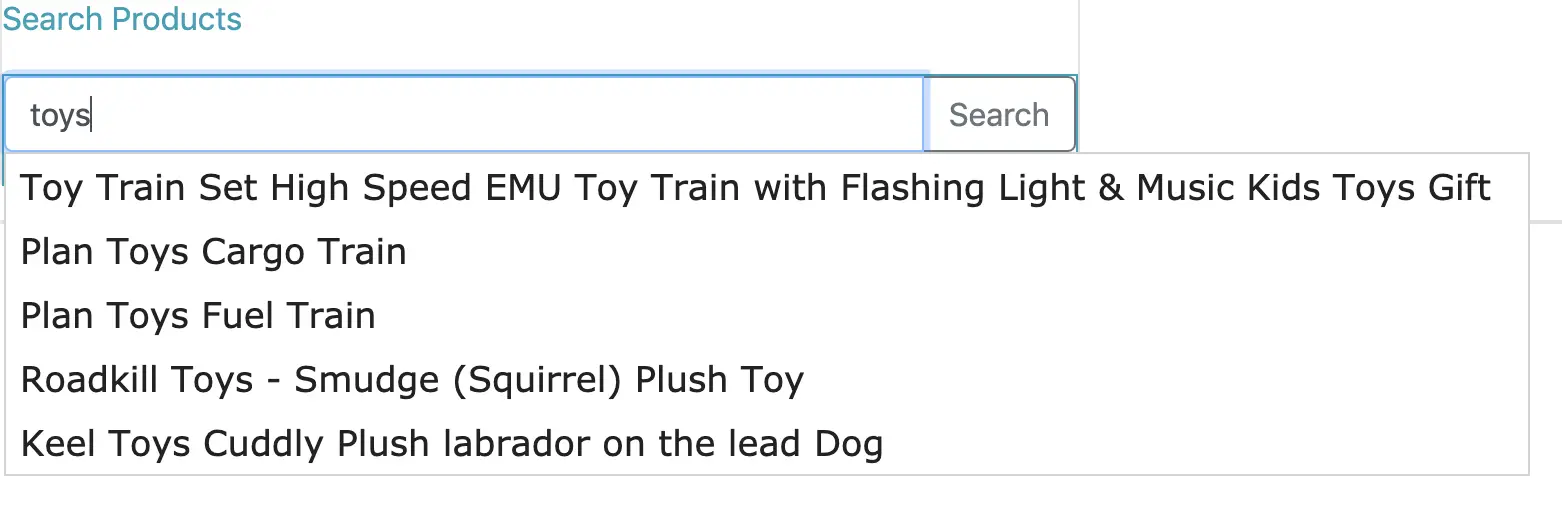 Мы создадим предложения автозаполнения для поисковых запросов пользователя. Затем выполните поиск продуктов по названию или описанию, точно соответствующему поисковому тексту, введенному пользователем. Для реализации этого варианта использования мы создадим две поисковые службы:
Мы создадим предложения автозаполнения для поисковых запросов пользователя. Затем выполните поиск продуктов по названию или описанию, точно соответствующему поисковому тексту, введенному пользователем. Для реализации этого варианта использования мы создадим две поисковые службы:
- Получение поисковых предложений для функции автозаполнения
- Обработка поиска продуктов на основе поискового запроса пользователя
Класс Service ProductSearchService будет содержать методы для поиска и получения предложений.
Создание индекса поиска продуктов
Это productindex тот же индекс, который мы использовали ранее для запуска тестов JUnit. Сначала мы удалим productindex Elasticsearch REST API, чтобы он productindex создавался заново во время запуска приложения с продуктами, загруженными из нашего образца набора данных, состоящего из 50 продуктов модной линейки:
curl -X DELETE http://localhost:9200/productindex
Мы получим сообщение {"acknowledged": true}, если операция удаления прошла успешно.
Теперь давайте создадим индекс для продуктов в нашем ассортименте. Для построения нашего индекса мы будем использовать образец набора данных из пятидесяти продуктов. Товары расположены в виде отдельных строк в файле CSV.
Каждая строка имеет три атрибута — идентификатор, имя и описание. Мы хотим, чтобы индекс создавался во время запуска приложения. Обратите внимание, что в реальных производственных средах создание индекса должно быть отдельным процессом. Мы прочитаем каждую строку CSV и добавим ее в индекс продукта:
@SpringBootApplication
@Slf4j
public class ProductsearchappApplication {
...
@PostConstruct
public void buildIndex() {
esOps.indexOps(Product.class).refresh();
productRepo.saveAll(prepareDataset());
}
private Collection<Product> prepareDataset() {
Resource resource = new ClassPathResource("fashion-products.csv");
...
return productList;
}
}
В этом фрагменте мы выполняем некоторую предварительную обработку, считывая строки из набора данных и передавая их методу saveAll() репозитория для добавления продуктов в индекс.
При запуске приложения мы видим приведенные ниже журналы трассировки при запуске приложения.
...Sending request POST /_bulk?timeout=1m with parameters:
Request body: {"index":{"_index":"productindex"}}
{"_class":"io.pratik.elasticsearch.productsearchapp.Product","name":"Hornby 2014 Catalogue","description":"Product Desc..talogue","manufacturer":"Hornby"}
{"index":{"_index":"productindex"}}
{"_class":"io.pratik.elasticsearch.productsearchapp.Product","name":"FunkyBuys..","description":"Size Name:Lar..& Smoke","manufacturer":"FunkyBuys"}
{"index":{"_index":"productindex"}}
.
...
Поиск продуктов с помощью многополевого и нечеткого поиска
Вот как мы обрабатываем поисковый запрос, когда отправляем поисковый запрос в метод processSearch():
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
private ElasticsearchOperations elasticsearchOperations;
public List<Product> processSearch(final String query) {
log.info("Search with query {}", query);
// 1. Create query on multiple fields enabling fuzzy search
QueryBuilder queryBuilder =
QueryBuilders
.multiMatchQuery(query, "name", "description")
.fuzziness(Fuzziness.AUTO);
Query searchQuery = new NativeSearchQueryBuilder()
.withFilter(queryBuilder)
.build();
// 2. Execute search
SearchHits<Product> productHits =
elasticsearchOperations
.search(searchQuery, Product.class,
IndexCoordinates.of(PRODUCT_INDEX));
// 3. Map searchHits to product list
List<Product> productMatches = new ArrayList<Product>();
productHits.forEach(searchHit->{
productMatches.add(searchHit.getContent());
});
return productMatches;
}
...
}
Здесь мы выполняем поиск по нескольким полям — имени и описанию. Мы также прикрепляем значок fuzziness() для поиска близко соответствующего текста, чтобы учесть орфографические ошибки.
Получение предложений с помощью поиска по подстановочным знакам
Далее мы создаем функцию автозаполнения для текстового поля поиска. Когда мы вводим текст в поле поиска, мы получаем предложения, выполняя поиск по подстановочным знакам с помощью символов, введенных в поле поиска.
Мы создаем эту функцию в fetchSuggestions() методе, показанном здесь:
@Service
@Slf4j
public class ProductSearchService {
private static final String PRODUCT_INDEX = "productindex";
public List<String> fetchSuggestions(String query) {
QueryBuilder queryBuilder = QueryBuilders
.wildcardQuery("name", query+"*");
Query searchQuery = new NativeSearchQueryBuilder()
.withFilter(queryBuilder)
.withPageable(PageRequest.of(0, 5))
.build();
SearchHits<Product> searchSuggestions =
elasticsearchOperations.search(searchQuery,
Product.class,
IndexCoordinates.of(PRODUCT_INDEX));
List<String> suggestions = new ArrayList<String>();
searchSuggestions.getSearchHits().forEach(searchHit->{
suggestions.add(searchHit.getContent().getName());
});
return suggestions;
}
}
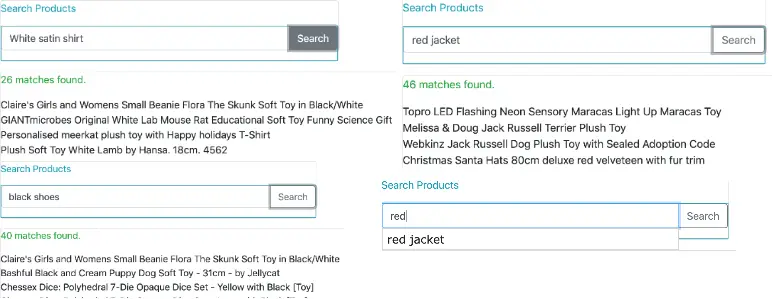
Мы используем запрос с подстановочными знаками в виде текста ввода поиска, к которому добавляется *так, что если мы введем «красный», мы получим предложения, начинающиеся с «красного». С помощью этого метода мы ограничиваем количество предложений до 5 withPageable(). Некоторые скриншоты результатов поиска из запущенного приложения можно увидеть здесь:
 Заключение
Заключение
В этой статье мы представили основные операции Elasticsearch — индексирование документов, массовое индексирование и поиск — которые предоставляются в виде REST API. Query DSL в сочетании с различными анализаторами делает поиск очень эффективным.
Spring Data Elasticsearch предоставляет удобные интерфейсы для доступа к этим операциям в приложении с помощью репозиториев данных Spring или ElasticsearchRestTemplate.
Наконец мы создали приложение, в котором увидели, как возможности массового индексирования и поиска Elasticsearch можно использовать в приложении, близком к реальному.

